Handbuch Rule Engine
Die Analytics Rule Engine verwendet Apache Flink, um einen Stream-Verarbeitungsdienst für die Event Engine-Funktion bereitzustellen. Dieses Dokument richtet sich an praxiserfahrene Teams, die Informationen über die CA Automic-Implementierung von Flink benötigen.
Hinweise:
- Weitere technischen Details zu Flink finden Sie unter: https://flink.apache.org/
- Dieses Dokument richtet sich an erfahrene Benutzer von Apache Flink. Es setzt voraus, dass Sie über Grundkenntnisse in den Themenbereichen verfügen.
Diese Seite beinhaltet Folgendes:
Warum Flink als Rule Engine verwendet wird
- Das Flink Stream Processing Framework ist schnell, zuverlässig und effizient
- Eine skalierbare Lösung, die auf 1 bis n Maschinen läuft
- Entfernt Load Balancing von der AE
Siehe: http://flink.apache.org/introduction.html#features-why-flink
Event Engine Ablauf
Da die Rule Engine auf Flink basiert, bleibt die Architektur weiterhin gleich.

Interaktion der Rule Engine mit Analytics
Die Schnittstelle zwischen Analytics und der Rule Engine wird mittels der Datei application.properties konfiguriert, die sich im folgenden Verzeichnis befindet: <Automic>/Automation.Platform/Analytics/backend.
Wichtig! collector.events.enabled ist standardmäßig deaktiviert (wenn Sie den One-Installer nicht verwenden) und muss explizit auf true gesetzt werden.
Beispiel für die Standardkonfiguration der Rule Engine:
##################### ## Ereignisaufnahme # ##################### # Ereignis aktivieren/deaktivieren collector.events.enabled=true ########################## ## Einstellungen für die Rule Engine ## ########################## # Flink-Job-Manager flink.host=localhost #flink.port=6123 #flink.web_port=8081 # Mit SSL eine Verbindung zu Flink herstellen #flink.use_ssl=false # SSL-Zertifikat überprüfen #flink.disable_self_signed_certificates=true # Job-Überwachungsintervall #flink.monitoring_interval_seconds=60 # Heartbeat-Intervall für die Prüfung auf abgebrochene Jobs #flink.monitoring_heartbeat_interval_minutes=3
Ereignisse verbrauchen
Kafka verwendet Themen, sogenannte Topics, als Begriff, um verschiedene Datenströme zu trennen. Die Rule Engine verwendet die Ereignisdefinition als Entity, wobei pro Mandant und Ereignisdefinition ein separates Kafka-Topic vorhanden ist.
Regeln ausführen
- Eine Regel ist kein Job und enthält keine JCL
- Regeln sind ein Subtyp von Ereignis-Objekten (EVTN) (in Automation Engine-Worten ausgedrückt), d. h. sie sind ähnlich zu Dateiereignissen
Wie eingehende Daten mit der Rule Engine umgewandelt werden
Das folgende Diagramm zeigt, wie Daten vom IA-Agenten über die Streaming-Plattform bis zur Rule Engine verarbeitet werden.
Hinweis: Ein Ereignistopic der Streaming-Plattform (Kafka) pro Mandant, z. B. 99_Ereignisse.
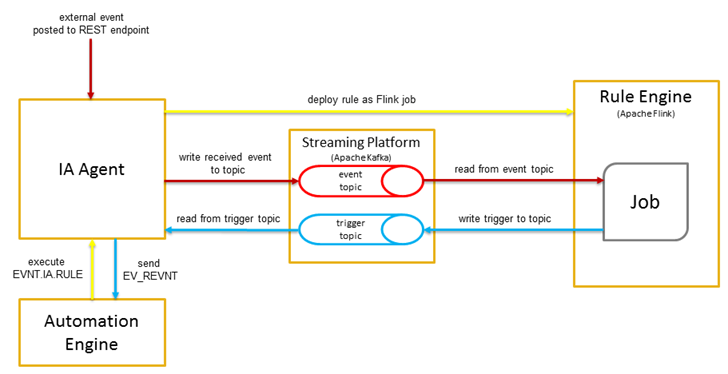
---------: Ausführen einer Regel
--------: Aufnehmen von externen Ereignissen
--------: Auslösen, wenn eingehende Ereignisse mit einer Regel übereinstimmen