Handbuch für die Streaming-Plattform
Die Analytics Streaming-Plattform nutzt Apache Kafka und Zookeeper, um einen Service für Meldungs-Queue/Speicher und Koordinierung für die Event Engine bereitzustellen. Dieses Dokument richtet sich an praxiserfahrene Teams, die Informationen über die internen Abläufe der Implementierung Kafka und Zookeeper benötigen.CA Automic
Wichtig! Beachten Sie, dass es sich hierbei nicht um ein umfangreiches Dokument zu den Technologien handelt, die zur Integration der Analytics Streaming-Plattform verwendet werden, sondern um die Methoden zur Bereitstellung der Adaption von Apache Kafka und Zookeeper.CA Automic
Hinweise:
- Ausführliche Informationen zu den technischen Details von Kafka finden Sie unter: https://kafka.apache.org
- Ausführliche Informationen zu den technischen Details von Zookeeper finden Sie unter: https://zookeeper.apache.org/
- Dieses Dokument richtet sich an erfahrene Benutzer von Apache Kafka und Zookeeper. Es setzt voraus, dass Sie über Grundkenntnisse in den Themenbereichen verfügen.
Diese Seite beinhaltet Folgendes:
Architektur
Da die Streaming-Plattform auf Kafka und Zookeeper basiert, bleibt die Architektur weiterhin gleich.
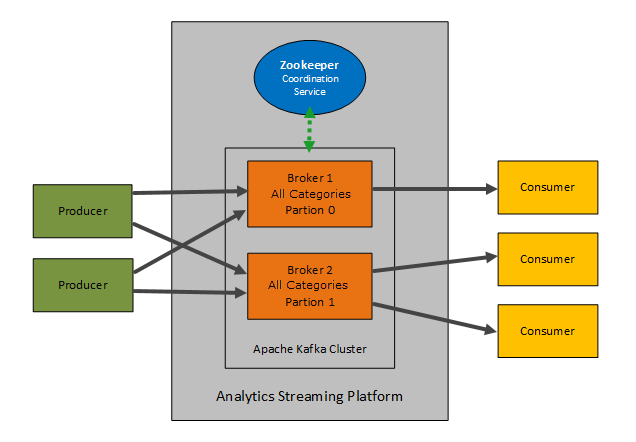
Interaktion der Streaming-Plattform mit Analytics
Die Schnittstelle zwischen Analytics und der Streaming-Plattform erfolgt über die Datei application.properties im folgenden Verzeichnis: <Automic>/Automation.Platform/Analytics/backend.
Hinweis: Alle Kollektoren sind standardmäßig aktiviert.
Die Event Engine hat zwei Topics, die in der Streaming-Plattform definiert sind:
- events für Ereignisse, die auf dem REST-Endpunkt im IA-Agenten gepostet werden.
- trigger, wenn Jobs von der Rule Engine (Flink) Triggermeldungen schreiben, die dann vom IA-Agenten verbraucht werden.
Siehe Kategorien (in Kafka als Topics bezeichnet)
Beispiel für die Standardkonfiguration der Streaming-Plattform:
# Kafka (Streaming-Plattform) ####### # Angabe von Kafka-Hosts
kafka.bootstrap_servers=localhost:9092 #Kafka Verbraucher und Hersteller #Standard: Konfigurationen für Kafka-Verbraucher können überschrieben werden #*globally: kafka.consumer_configs.default[<Einstellung>]=<Wert> #*specific: kafka.consumer_configs.<Verbraucher>[<Einstellung>]=<Wert> # #Standard: Konfigurationen für Kafka-Hersteller können überschrieben werden #*globally: kafka.producer_configs.default[<Einstellung>]=<Wert> #*specific: kafka.producer_configs.<producer>[<Einstellung>]=<Wert> # #Verbraucher/Hersteller, die verwendet werden: #*edda_trigger: zum Lesen/Schreiben löst eine Regel der Rule Engine aus #*edda_events: wird verwendet, um eingehende Ereignisse, die von der Rule Engine verarbeitet werden, zu lesen/schreiben #kafka.producer_configs.edda_trigger[acks]=all #kafka.producer_configs.edda_events[acks]=all
#Kafka Topics
#
#Eigenschaften zum Erstellen eines Topics konfigurieren
#*globally:kafka.topic_configs.default.default.<Einstellung>=<Wert>
#*pro dataspace:kafka.topic_configs.<Datenbereich>.default.<Einstellung>=<Wert>
# * pro Thema: kafka.topic_configs.<Datenbereich>.<Topic>.<Einstellung>=<Wert>
#
#Die folgenden Einstellungen für Kafka-Topics stehen zur Verfügung
#*partitions: Anzahl der Partitionen, die für jedes Topic verwendet werden sollten
#*replication_factor: Anzahl der Replikas pro Partition
#*rack_aware_mode: verteilte Replikas einer Partition über mehrere Racks (mögliche Werte: DISABLED, ENFORCED, SAFE)
#kafka.topic_configs.default.default.partitions=1
#kafka.topic_configs.default.default.replication_factor=1
#kafka.topic_configs.default.default.rack_aware_mode=DISABLED
Datenorganisation (Datenbereiche und Kategorien)
Namenskonvention der Streaming-Plattform
Die Streaming-Plattform - die Datenströme sind getrennt und leicht identifizierbar. Die Lösung von CA Automic besteht darin, Identifikatoren und Namen zu verwenden, weshalb das folgende Format verwendet wird:
<uuid>_ds-<dataspaceName>_<name>
-
Die rot markierte Anwendungs-ID ermöglicht die Trennung zwischen verschiedenen Anwendungsinstanzen, die sich dieselbe Streaming-Plattform-Installation teilen (z. B. die Trennung zwischen mehreren Analytics Backend-Installationen oder zwischen Analytics Backend und kundeneigenen Anwendungen).
Die <uuid> (unique identifier) identifiziert die Anwendungsinstanz.
-
Die in orange gekennzeichnete Datenbereich-ID stellt eine Trennung der verschiedenen Hersteller/Verbraucher innerhalb derselben Anwendung sicher.
Sie besteht aus dem Präfix dataspace, gefolgt vom Datenbereich-Namen in eckigen Klammern.
-
Der letzte Abschnitt in grün besteht aus einem Namenselement. Die Event Engine verwendet lediglich einen Topicnamen (z. B. Ereignisse oder Trigger).
Siehe auch: Kategorien (in Kafka als Topics bezeichnet)
Datenbereiche
Datenbereiche sind logische Organisationsstrukturen, die bei der Unterscheidung von Kategorien helfen, die von verschiedenen Komponenten verwaltet werden.
<Automic>/Automation.Platform/Analytics/backend

Kategorien (in Kafka als Topics bezeichnet)
Hinweis :
- Bei der Event Engine wird der allgemeine Kafka-Begriff Topic und nicht der Begriff Kategorien verwendet.
- Kategorien sind immer Mehrfachabonnenten, d. h. ein Topic kann null, einen oder viele Nutzer haben, die die darin geschriebenen Daten abonnieren.
Wie bereits beschrieben, werden Daten in der Streaming-Plattform in Datenbereichen organisiert und innerhalb jedes Datenbereichs gibt es Kategorien. Eine Kategorie in einem Datenbereich wird über einen bestimmten Satz von Präfixen abgebildet.
Hinweis: Standardmäßig abonnieren Nutzer alle Topics, um die Leistung zu verbessern.
So fließen Daten durch die Streaming-Plattform
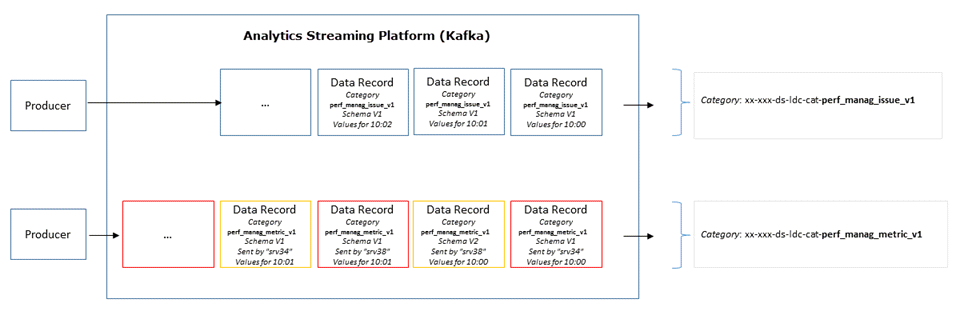
Sobald ein Nutzer einen Hersteller-Datensatz verbraucht hat, verschiebt die Streaming-Plattform den Zugriff und nur neuere Datensätze werden von dem betreffenden Nutzer konsumiert. Jeder neue Nutzer, der einen Hersteller abonniert, verbraucht ältere Datensätze in Abhängigkeit von der eingestellten Aufbewahrungsfrist.
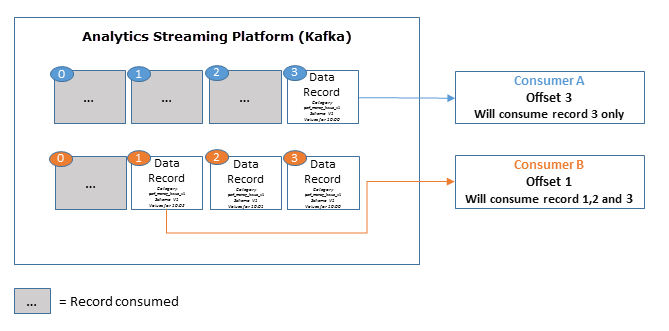
Parallel zur Standardimplementierung von Kafka speichert die Streaming-Plattform alle veröffentlichten Datensätze, unabhängig davon, ob sie verbraucht wurden. Dies geschieht über die konfigurierbare Aufbewahrungsfrist (Standarddauer ist sieben Tage).
Beispiel:
Wenn die Aufbewahrungsrichtlinie auf zwei Tage festgelegt ist, können Datensätze in diesem Zeitraum verbraucht werden, danach werden sie verworfen, um Speicherplatz zu schaffen.