Google Cloud Dataflow Jobs: Run Jobs
Automic Automation Dataflow Run Jobs allow you to start Google Cloud Dataflow Template Jobs in your Dataflow environment from Automic Automation and monitor them to completion.
Dataflow Templates allow you to package a Dataflow pipeline for deployment. If you have the correct permissions, you can use pre-built templates that Google has provided for common scenarios; However, developers can also create their own custom Dataflow templates, which can then be directly deployed by a data scientist, for example.
To start a Dataflow Template job successfully, you have to define the parameters that you want to pass to the application. These parameters allow you to control the behavior and activities at runtime.
This page includes the following:
Defining Google Cloud Dataflow Run Job Properties
On the Run Job page, you define the parameters relevant to start the template configuration on Dataflow:
-
Connection
Select the Dataflow Connection object containing the relevant information to connect to the application.
To search for a Connection object, start typing its name to limit the list of the objects that match your input.
-
Project ID
Enter the ID of the project in the Google Cloud Service (GCS) system containing the relevant execution configuration.
-
Location
Enter the location (region) in which your data is stored and processed.
-
Job Name
The name of the job you want to define as a unique name.
-
Template Path
Path to the GCS template location.
Examples of pre-built open source Dataflow templates that you can use for common scenarios:
-
WORD_COUNT
Template for the word count
gs://dataflow-templates-us-central1/latest/Word_Count
-
GCS_Text_to_Cloud_Spanner
Text file on cloud storage to cloud spanner
gs://dataflow-templates-us-central1/latest/GCS_Text_to_Cloud_Spanner
-
Firestore_to_GCS_Text
Firestore (datastore mode) to text files on cloud storage
gs://dataflow-templates-us-central1/latest/Firestore_to_GCS_Text
-
Spanner_to_GCS_Text
Cloud spanner to text files on cloud storage
gs://dataflow-templates-us-central1/latest/Spanner_to_GCS_Text
-
GCS_Text_to_BigQuery
Text files on cloud storage to BigQuery
gs://dataflow-templates-us-central1/latest/GCS_Text_to_BigQuery
-
GCS_Text_to_Firestore
Text files on cloud storage to firestore (datastore mode)
gs://dataflow-templates-us-central1/latest/GCS_Text_to_Firestore
-
Cloud_Bigtable_to_GCS_Json
Cloud Bigtable to JSON
gs://dataflow-templates-us-central1/latest/Cloud_Bigtable_to_GCS_Json
-
Bulk_Compress_GCS_Files
Bulk compress files on cloud storage
gs://dataflow-templates-us-central1/latest/Bulk_Compress_GCS_Files
-
Bulk_Decompress_GCS_Files
Bulk decompress files on cloud storage
gs://dataflow-templates-us-central1/latest/Bulk_Decompress_GCS_Files
-
-
Parameters
(Optional) Depending on the template you use, define one of the following:
-
None (default)
Select this option if you do not want to pass any parameters to GCP Dataflow.
-
JSON File Path
Use the JSON File Path field to define the path to the JSON file containing the attributes that you want to pass to the application. Make sure that the file is available on the Agent machine (host).
-
JSON
Use the JSON field to enter the JSON payload definition.
Tip: You can get it from the Dataflow console's "Create job from template" section, which is available for each template. Once the required parameters are filled in for the related template, click "Equivalent REST" in the "Optional Parameters" section to make the JSON parameters visible. You can now copy and paste the parts you require.
For example: {"inputFile": "gs://casw-bucket/first-folder/testfileCopy4.txt", "output": "gs://casw-bucket/test_folder"}
-
-
Environment
(Optional) The environment can contain additional information that might be required to run the job. You can select:
-
None (default)
Select this option if you do not want to pass any parameters to GCP Dataflow.
-
JSON File Path
Use the JSON File Path field to define the path to the JSON file containing the attributes that you want to pass to the application. Make sure that the file is available on the Agent machine (host).
-
JSON
Use the JSON field to enter the JSON payload definition.
Tip: You can get it from the Dataflow console's "Create job from template" section, which is available for each template. Once the required parameters are filled in for the related template, click "Equivalent REST" in the "Optional Parameters" section to make the JSON parameters visible. You can now copy and paste the parts you require.
For example: {"tempLocation":"gs://dataflow-staging-us-central1-562431588198/temp"}
-
-
The AWI shows the two optional fields, Parameters and Environment, which you can define separately. However, the requests are sent to the GCS system as one.
-
There are many options available to define the JSON payload regardless of whether you do so in the Parameters or Environment field. For more information and examples of the JSON definition, see Defining the JSON
-
Get Execution Logs
Allows you to select when to get trace logs from the GCS:
-
On error only (default)
A trace log is only written if the job fails.
Note:If the job cannot start successfully, for example due to incorrect JSON payload parameters, no log can be written.
-
Always
A trace log is always written, regardless of the job status. You see the results in the Agent log types LOGS and MET. For details, see Monitoring Google Cloud Dataflow Jobs
Note:Enabling this parameter may increase the job's runtime.
-
Defining the JSON
This section gives you examples of how you could define the JSON field when defining a Run Job. You have different options available.
Simple JSON Definition
The first option to define the JSON field is a simple payload definition. To do so, make sure you define the parameters required to define the pipeline, such as name, type, default value, and so on.
Using Variables
You can also use variables in the payload definition.
Example
In the JSON field, enter the following:
&PIPELINEPARAM#
If the variable is not defined yet, you must define it now. You do it on the Variables page of the Run Job definition:
(Click to expand)
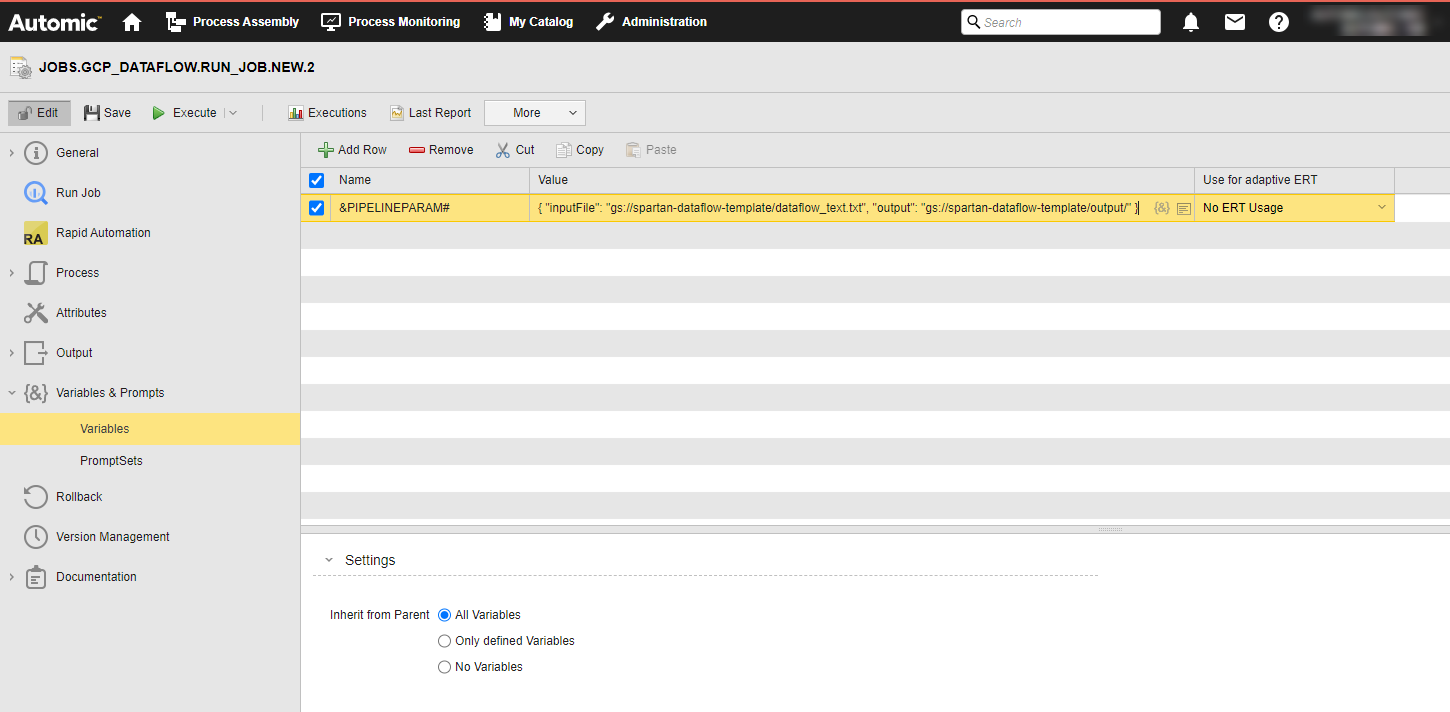
When you execute the Job, the variables will be replaced with the value you have just defined. This is visible in the Agent log (PLOG), see Monitoring Google Cloud Dataflow Jobs.
Google Cloud Dataflow Run Job in a Workflow
You can also use the JSON field if you want to include a Run Job in a Workflow and you want to use Automation Engine variables in it.
Example
In the Workflow, a Script object (SCRI) with the variable definition relevant to the parameters required in the Job object -Project ID, Location, Job Name, and Template Path- precedes your Run Job:
(Click to expand)
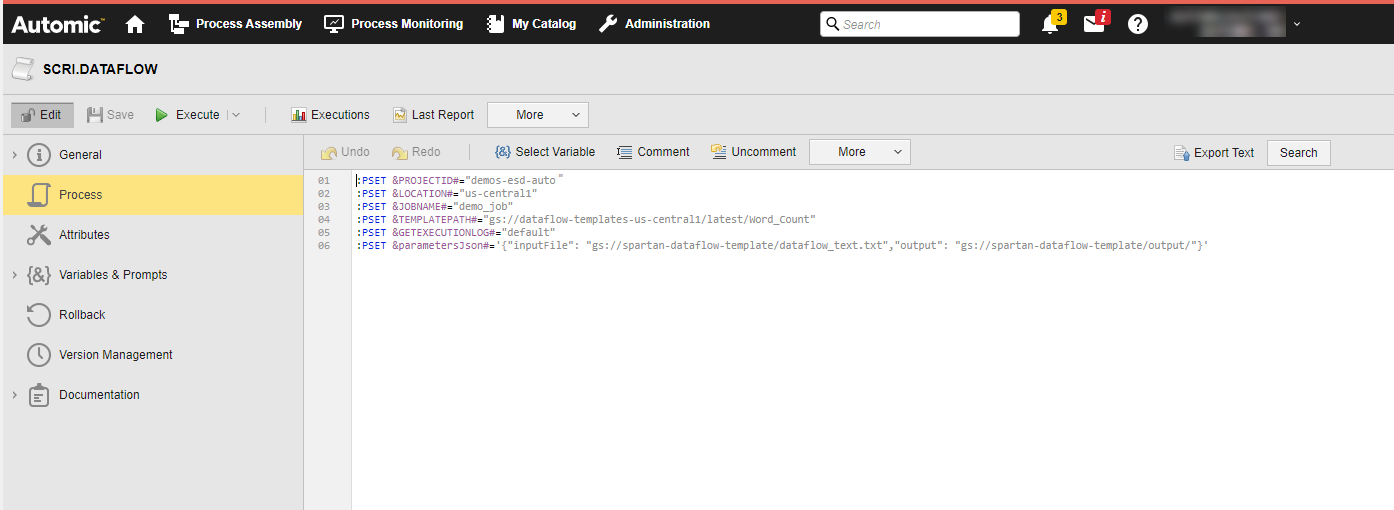
In the Run Job definition, you include those variables:
(Click to expand)
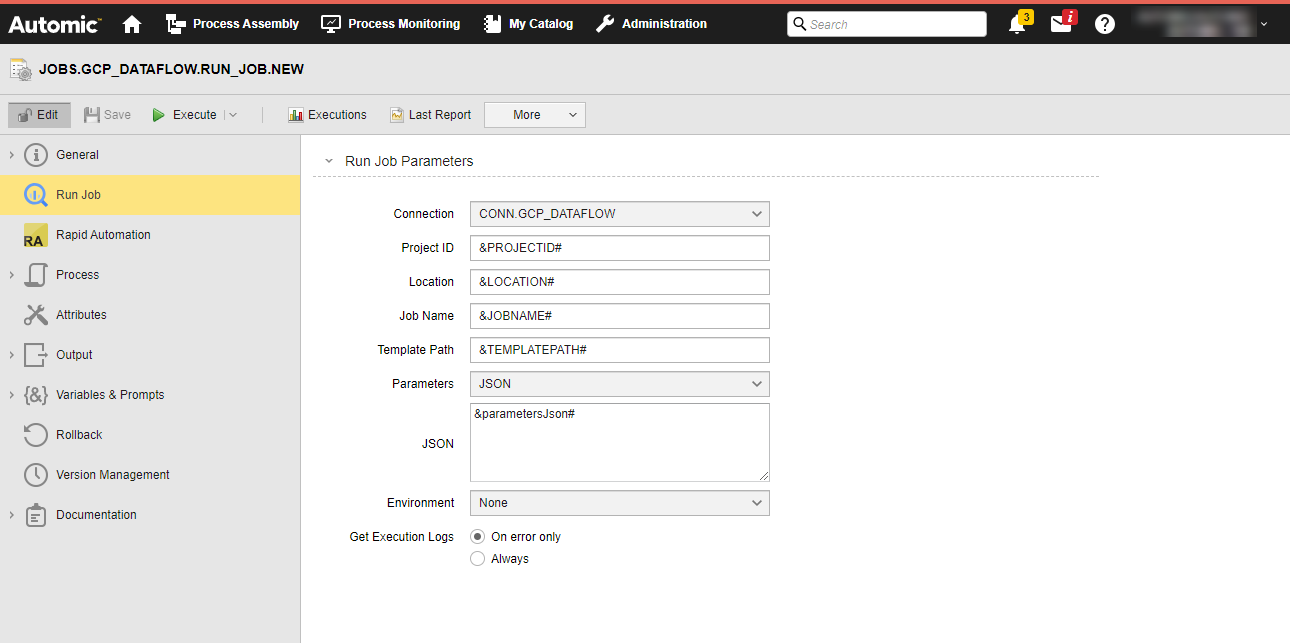
When the Job is executed, the variables will be replaced with the value you have just defined. This is visible in the Agent (PLOG) report, see Monitoring Google Cloud Dataflow Jobs.
See also: