Rule Engine (Flink) Operational Guide
The Analytics Rule Engine (Flink) uses Apache Flink to deliver a stream processing service for Event Engine feature. This document is aimed at experienced operational teams that require information about the internal workings of Automic's implementation Flink .
Note this is not an extensive guide to the technologies used to incorporate the Rule Engine, it outlines the methods used to deploy Automic's adaptation of Apache Flink.
For extensive information regarding the technical details of Flink see: https://flink.apache.org/
From this point on the term Rule Engine used as opposed to Flink, however when explicitly necessary Flink will be referred to.
This document is aimed at experience users of Apache Flink, it presumes that you have some basic knowledge of the topics outline below.
Why Flink is used as the Rule Engine
- Apacke Flink stream processing framework (fast, reliable and efficient)
- Runs on 1 to n machines (scalable)
- Takes care of load balancing (away from AE)
See: http://flink.apache.org/introduction.html#features-why-flink
Architecture
As the Rule Engine is based on Flink architecture remains common.

How the Rule Engine interfaces with Analytics
The interface between Analytics and the Rule Engine is made through the application.properties file located in following directory: <Automic>/Automation.Platform/Analytics/backend.
collector.events.enabled is disabled by default (if not using the one-installer) and needs to be set to true explicitly.
Example of the default Rule Engine configuration:
##################### ## Events ingestion # ##################### # Enable/disable event ingestion collector.events.enabled=true ########################## ## Rule Engine settings ## ########################## # Flink job manager flink.host=localhost #flink.port=6124 #flink.web_port=8081 # Use SSL for connecting to Flink #flink.use_ssl=false # Verify SSL certificate #flink.disable_self_signed_certificates=true # Job monitoring interval #flink.monitoring_interval_seconds=60 # Heartbeat interval to check for abandoned jobs #flink.monitoring_heartbeat_interval_minutes=3
Consuming Events
- Kafka uses "Topics" as term to separate different streams of data. The Rule Engine uses "Event definition" as the entity, where there’s one separate Kafka topic per client and event definition.
Executing Rules
• A rule is not a job and does not contain any JCL
• Rules are a subtype of Event (EVNT) objects (in Automation Engine terms) so they are more related to file events
How incoming data is transformed with the Rule Engine
The diagram below shows how data is processed from IA Agent to Streaming Platform and to the Rule Engine.
There is one Streaming Platform (Kafka) event topic per client for example 99_events.
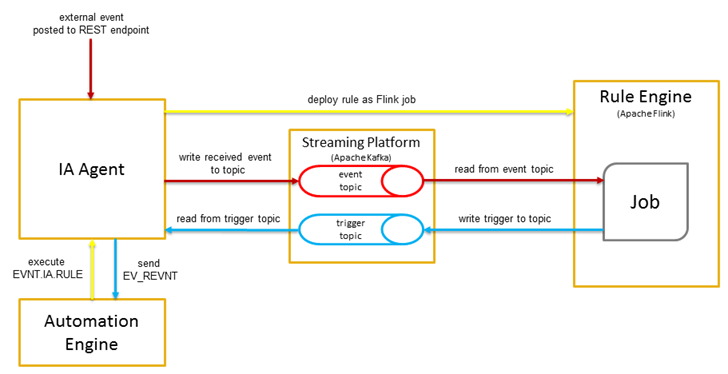
---------: execute a rule
--------: Ingest external events
--------: Trigger if incoming events match a rule
Enabling Event Processing