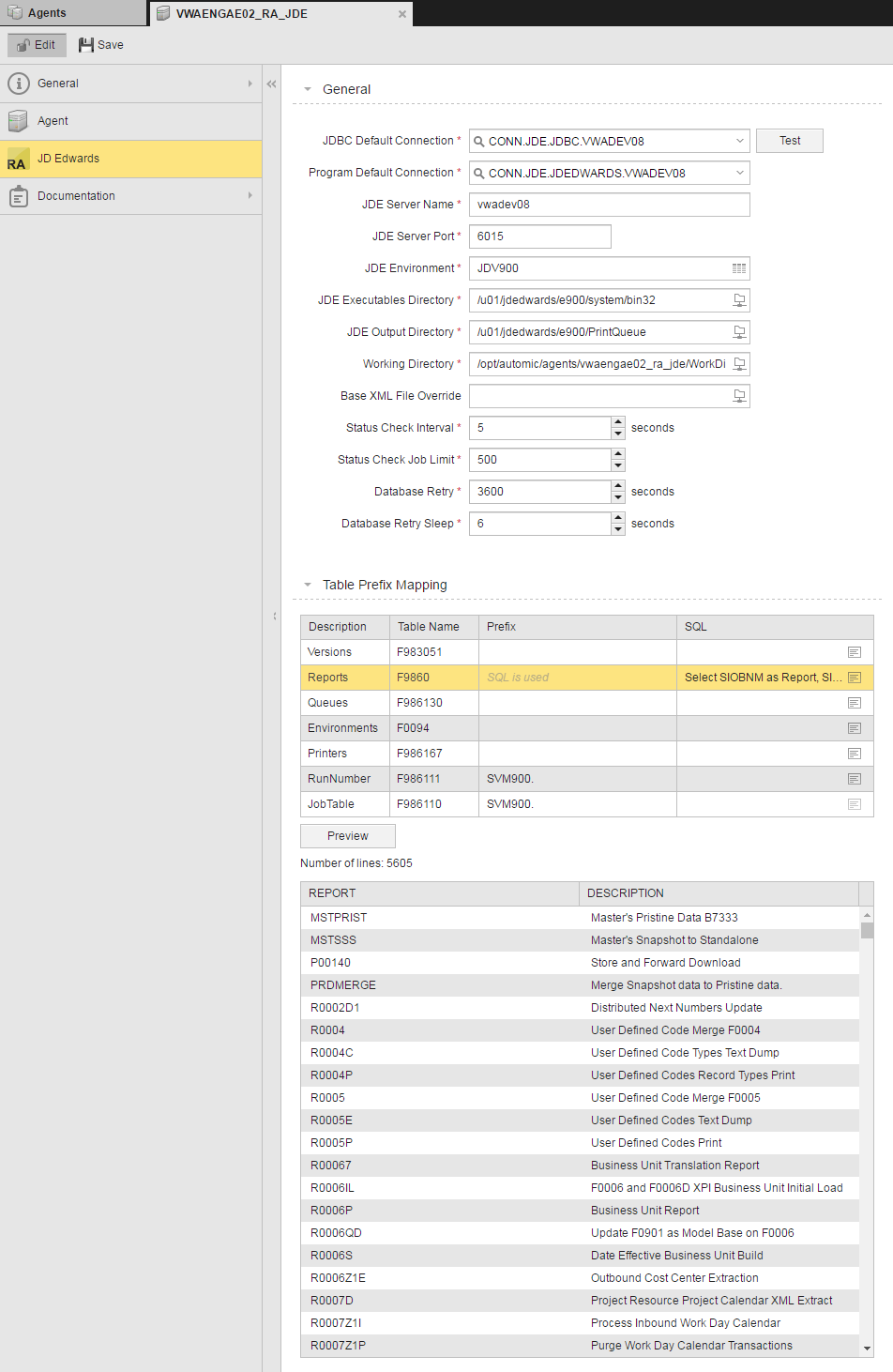
JD Edwards agent settings allow you to configuration the agent and set defaults for the agent integration. You can map table prefixes and define custom SQL for predefined SQL and tables.
Create a JD Edwards agent and specify agent settings on the JD Edwards page. JD Edwards agent settings allow you to configuration the agent and set defaults for the agent integration.
Agent settings are shown above and described in the table below.
| Field | Description |
|---|---|
|
JDBC Default Connection |
The JDBC connection object used to connect to JD Edwards. For more information, see topic Creating JD Edwards JDBC and Program Connection Objects. You can test the connection using the Test button. |
|
Program Defaul Connection |
The default program connection object used to run jobs. For more information, see topic Creating JD Edwards JDBC and Program Connection Objects. |
|
JDE Server Name |
The name of the JD Edwards server. The JD Edwards agent uses the server name specified here to query for task statuses. This field is case-sensitive. If the server name does not match JCEXEHOST in the Master Job Table (F986110), Tasks will not complete in the Automation Engine. |
|
JDE Server Port |
The port of the JD Edwards server. |
|
JDE Environment |
JD Edwards environment that the agent will submit jobs to. You can use the select icon to select the JD Edwards environment. |
|
JDE Executables Directory |
The directory where the runubexml and runube programs exist. You can use the browse icon to browse to and select a directory. |
|
Where JD Edwards output is located. Prior to JD Edwards 9.1.5, all the output files went to a PrintQueue folder. With a lot of files under that directory, it can be hard to keep organized. For JD Edwards 9.1.5 and above, you have the option to further group the files under subdirectories of the PrintQueue directory. You do this by adding the JDE.INI file on the JDE server (for example /u01/jde920/e920/ini/JDE.INI) to specify the format of the subdirectories. To do this, you edit the file under the [UBE] block and add an entry: PrintQueuePathFormat=EXEHOST/JOBQ/SBMDATE This entry has three parameters. You can use the parameters in any order (without using duplicates), and the order matters. For example, with: PrintQueuePathFormat=JOBQ/SBMDATE The output files will be organized by queue, then by dates, having directory structure like: /PrintQueue/QBATCH/20160628 When you define JD Edwards RA agent, the output directory has to match the entry in the JDE.INI file. For example, if the entry is JOBQ/SBMDATE, the output directory will be like: /u01/jde920/e920/PrintQueue/{QUEUE}/{date} If the entry is EXEHOST/JOBQ/SBMDATE, the output directory will be like: /u01/jde920/e920/PrintQueue/{Host}/{QUEUE}/{date} Notice the three replacement value have to be {Host}, {QUEUE}, and {date} to match EXEHOST, JOBQUEUE, and SBDATE, which are case sensitive. They are replaced with real values at runtime. You can use the browse icon to browse to and select a directory. |
|
|
Working Directory |
The directory in which the JD Edwards agent creates scripts and from which it works. You can use the browse icon to browse to and select a directory. |
|
Optionally provides a base template for the first stage of the runubexml file to start its bootstrapping. A custom template for the first stage of the runubexml file is usually not necessary. If you don’t need one, leave this field blank. You can use the browse icon to browse to and select a directory. |
|
|
Status Check Seconds |
Number of seconds to wait before polling for status change. |
|
Status Check Job Limit |
Limits the number of jobs to check statuses for per query. Due to database limitations this must be less than 1000. |
|
Number of seconds to attempt to reconnect to a failed database connection. |
|
|
Database Retry Sleep |
Number of seconds to sleep between database reconnection attempts. |
Database Reconnect
The agent attempts to recover from temporary, unexpected database outages. However, in some situations the agent may not be able to recover entirely. Bringing down the database while the agent is running can lead to timing errors or data corruption. It is always best practice whenever possible to stop the agent before bringing down the database.
If the agent tries to run a task and encounters a database connection failure, the Automation Engine will consider the agent unavailable so that no other jobs will be submitted until the database connection has been restored. During the time that the agent is unavailable if a new task is submitted, you will see messages similar to the ones below:
2/10/2011 9:28:35 AM - U0011113 Task with RunID '0001137033' will be re-started as soon as host 'JDE' is active again or the previous error has been corrected.
2/10/2011 9:28:35 AM - U0011000 'R014021' (RunID: '0001137033') could not be started on 'JDE'. See next message.
The agent will attempt to reconnect for the amount of time specified in the Database Retry field. If it is successful, it will consider the agent available, complete the running task, and continue processing all other waiting tasks. If it fails to reconnect in the time specified, it will abort the task and the agent will remain unavailable. For this case, the proper way to recover once the database issue has been resolved is to stop and restart the agent to re-establish the connection.
Mapping Table Prefixes or Defining SQL
The JD Edwards agent has predefined SQL and table names for the following:
| Table | Description |
|---|---|
| Versions | Used to select the report version from the Version field in UBEXML and UBE job definitions. |
| Reports | Used to select the report name from the Report field in UBEXML and UBE job definitions. |
| Queues | Used to select the job queue from the JDE Job Queue field in UBEXML and UBE job definitions. |
| Environments | Used to select the environment from the Environment field in UBEXML and UBE job definitions. |
| Printers | Used to select the printer from the Override Printer field in UBEXML and UBE job definitions. |
| RunNumber | Used for the JDEUBEJOB job type. |
| JobTable | The Master Job table. Because the query on this table is dependent on the agent’s running job list, you cannot define the SQL for this table. The Define SQL button does nothing if this row is selected. You can define a prefix for this table. |
In the Table Prefix Mappings section, you can either:

In the SQL statement, the {REPORT}, {VERSION}, {ENVIRONMENT}, {ROLE}, and {QUEUE} variables can be used. The example below uses the variable {REPORT} in the query for JDE Versions.

The variables are only substituted when the query is run from a job definition. They are not substituted when the query is checked with the Preview button. If you click Preview for a SQL statement where a variable is used, no results will be returned.
When no variables are included in a valid SQL statement, clicking the Preview button will return results at the bottom of the Table Prefix Mapping section.
Once you define a SQL statement, the value in the table’s Prefix column will read SQL is use and will no longer apply. If you define a custom SQL statement and you use a table name prefix, it must be included in your SQL statement.
After defining a SQL statement, you need to stop and restart the agent in order for it to take effect.