Streaming Platform (Kafka) Operational Guide
The Analytics Streaming Platform uses Apache Kafka and Zookeeper to deliver a message queue/storage and coordination service for DCS (Data Collection Service) and the Event Engine feature. This document is aimed at experienced operational teams that require information about the internal workings of Automic's implementation Kafka and Zookeeper.
Note this is not an extensive guide to the technologies used to incorporate Analytics Streaming Platform, it outlines the methods used to deploy Automic's adaptation of Apache Kafka and Zookeeper.
For extensive information regarding the technical details of Kafka see: https://kafka.apache.org
For extensive information regarding the technical details of Zookeeper see: https://zookeeper.apache.org/
From this point on the term Streaming Platform is used as opposed to Kafka, however when explicitly necessary Kafka will be referred to.
This document is aimed at experience users of Apache Kafka and Zookeeper, it presumes that you have some basic knowledge of the topics outline below.
Architecture
As the Streaming Platform is based on Kafka and Zookeeper the architecture remains common.
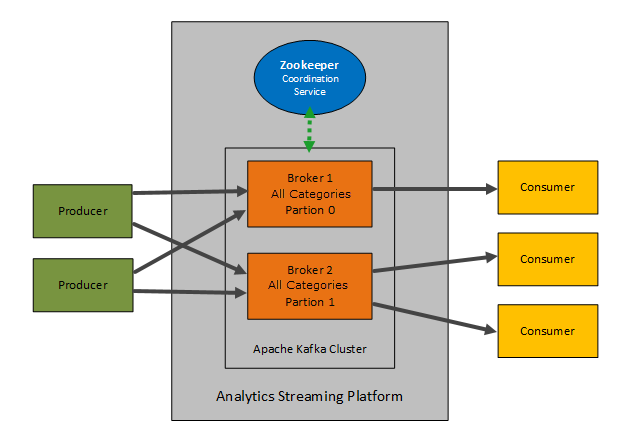
How the Streaming Platform interfaces with Analytics
The interface between Analytics and the Streaming Platform is made through the application.properties file located in following directory: <Automic>/Automation.Platform/Analytics/backend.
When the DCS is started, the Streaming Platform creates a number of topics (depending of the number of activated collectors).
Note all collectors are activated by default.
Analytics Event Engine and the DCS (Telemetry) feature both use the Streaming Platform, however they do not deal with data the same way.
The Event Engine feature has two topics defined in the Streaming Platform:
- "events" for Events posted to the REST endpoint in the IA Agent.
- "trigger" when Rule Engine (Flink) jobs write trigger messages that are then consumed by the IA Agent.
The DCS (telemetry) feature currently uses 27 topics, however the naming convention used to define a topic is known as a category. This is used as a prefix to distinguish individual metrics that are stored. See: Categories (Known as topics in Kafka)
Example of the default Streaming Platform configuration:
# Kafka (Streaming Platform) ####### # Specify Kafka hosts
kafka.bootstrap_servers=localhost:9092 #Kafka consumers and producers #Default Kafka consumer configs can be overridden #*globally: kafka.consumer_configs.default[<setting>]=<value> #*specific: kafka.consumer_configs.<consumer>[<setting>]=<value> # #Default Kafka producer configs can be overridden #*globally: kafka.producer_configs.default[<setting>]=<value> #*specific: kafka.producer_configs.<producer>[<setting>]=<value> # #Consumers/Producers that are used: #*edda_trigger:used to read/write triggers of an Rule Engine rule #*edda_events:used to read/write incoming events that are processed by the Rule Engine #*telemetry:used for Data Collection Service #kafka.producer_configs.edda_trigger[acks]=all #kafka.producer_configs.edda_events[acks]=all #kafka.producer_configs.telemetry[max.block.ms]=15000 #kafka.consumer_configs.telemetry[request.timeout.ms]=15000 #Kafka buffered producer configs #kafka.buffered_producer_configs.telemetry[queue.size]=10000 #kafka.buffered_producer_configs.telemetry[requeue.failed.data.records]=true #kafka.buffered_producer_configs.telemetry[error.logging.period.ms]=300000 #Kafka topics # #Configure topic creation properties #*globally:kafka.topic_configs.default.default.<setting>=<value> #*per dataspace:kafka.topic_configs.<dataspace>.default.<setting>=<value> #*per topic:kafka.topic_configs.<dataspace>.<topic>.<setting>=<value> # #The following Kafka topic settings are available #*partitions: number of partitions that should be used for each topic #*replication_factor:number of replicas per partition #*rack_aware_mode:spread replicas of one partition across multiple racks (possible values: DISABLED, ENFORCED, SAFE) #kafka.topic_configs.default.default.partitions=1 #kafka.topic_configs.default.default.replication_factor=1 #kafka.topic_configs.default.default.rack_aware_mode=DISABLED
Data Organization (Dataspaces, Categories and Schema)
Streaming Platform Naming Convention
Since DCS and the Event Engine feature use the Streaming Platform, data streams need to be separated and easily identifiable. Automic's solution is to use identifiers and names and therefore the following format has been adopted:
<uuid>_ds-<dataspaceName>_<name>
-
The application identifier denoted in red, allows for the separation between different application instances sharing the same Streaming Platform installation (e.g. separation between several Analytics Backend installations or between Analytics Backend and customers' own applications).
The <uuid> (unique identifier) identifies the application instance.
For example:
datastore.dataspaces[telemetry].categories[Metric].schemas[1].enabled=true.
-
The dataspace identifierdenoted in orange, ensures a separation of different producers /consumers in the same application (e.g. the separation of Event Engine data and DCS data).
It is composed of the prefix dataspace, followed by the dataspace name in square brackets .
For example:
datastore.dataspaces[telemetry].categories[Metric].schemas[1].enabled=true.
-
The last section in green is made up of a name item. The naming convention is different for the Event Engine feature and DCS. The Event Engine feature uses the simply a topic name (for example "events" or "trigger"). However the DCS uses the term category to define names.
For example:
datastore.dataspaces[telemetry].categories[Metric].schemas[1].enabled=true.
Also see: Categories (Known as topics in Kafka)
Dataspaces
Dataspaces are logical organizational structures that help differentiate categories managed by different components.
The default Dataspaces used by DCS (telemetry). Located in the telemetry.properties file, in following directory:
<Automic>/Automation.Platform/Analytics/backend

Categories (Known as topics in Kafka)
The Event Engine feature uses the generic Kafka term topic and does not use the term Categories.
When data is injected into the Streaming Platform it is organized into dataspaces / categories and for each category (topic) several schema versions are supported.
Categories are always multi-subscriber; that is, a topic can have zero, one, or many consumers that subscribe to the data written to it.
As previously described the Streaming Platform organizes data into Dataspaces and within each Dataspace there are Categories. A Category in a Dataspace is mapped using a specific set of prefixes.
Example of DCS Categories (Topic):
#Categories datastore.dataspaces[telemetry].schema_package=com.automic.analytics.telemetry.categories.schemas datastore.dataspaces[telemetry].categories[Metric].schemas[1].enabled=true datastore.dataspaces[telemetry].categories[Metric].schemas[2].enabled=true datastore.dataspaces[telemetry].categories[Metric].schemas[3].enabled=true datastore.dataspaces[telemetry].categories[Snapshot].schemas[1].enabled=true datastore.dataspaces[telemetry].categories[Snapshot].schemas[2].enabled=true
By default consumers are subscribed to all topics to improve performance.
For a list of Categories see: Catalog of DCS Data Categories
Schema
The Schema element is implemented by DCS only)
A Schema is a description of the data structure of a record type.
- Describes the information inside the Data Record
- Describes structure of the Data Records
- Indicates anonymized information that is shared with Automic
- Is used by Analytics to validate or reject data when it is injected (it allows verification of injected data)
- Allows efficient serialization and de-serialization of Data Records
- Versioning enable categories to be expanded in the future
A data record type is classified by 2 identifiers:
- The item type identifier (example: Metric)
- The version type identifier (example: V1)
Example:
The AEAgentsV1 schema
{
"namespace":"com.automic.analytics.telemetry.categories.schemas.AEAgentsV1",
"name":"AEAgentsV1",
"type":"record",
"doc": "AE Agents",
"fields": [
{"name":"timestamp", "type":"string", "doc": "AE Agent Snapshot timestamp"},
{"name":"agent_name", "type":"string", "doc": "AE Agent name", "anonymize": {"rules":["maskAllHash"]}},
{"name":"active", "type":"int", "doc": "PEER active = 1"},
{"name":"attr_type", "type":"string", "doc": "Attribute type corresponding to table UC_HTYP"},
{"name":"version", "type":"string", "doc": "Executor version"},
{"name":"ip_addr", "type":"string", "doc": "IP address", "anonymize": {"rules":["ruleSetIP"]}},
{"name":"port", "type":"int", "doc": "Port number"},
{"name":"software", "type":"string", "doc": "Software"},
{"name":"software_vers", "type":"string", "doc": "Software version"},
{"name":"license_class", "type":"string", "doc": "License class"},
{"name":"lic_category", "type":"string", "doc": "License calegory"},
{"name":"net_area", "type":"string", "doc": "The NetArea in which this Agent runs"}
]
}
The AEAgentsV2 schema with additional field
{
"namespace":"com.automic.analytics.telemetry.categories.schemas.AEAgentsV1",
"name":"AEAgentsV2",
"type":"record",
"doc": "AE Agents",
"fields": [
{"name":"timestamp", "type":"string", "doc": "AE Agent Snapshot timestamp"},
{"name":"agent_name", "type":"string", "doc": "AE Agent name", "anonymize": {"rules":["maskAllHash"]}},
{"name":"active", "type":"int", "doc": "PEER active = 1"},
{"name":"attr_type", "type":"string", "doc": "Attribute type corresponding to table UC_HTYP"},
{"name":"version", "type":"string", "doc": "Executor version"},
{"name":"ip_addr", "type":"string", "doc": "IP address", "anonymize": {"rules":["ruleSetIP"]}},
{"name":"port", "type":"int", "doc": "Port number"},
{"name":"software", "type":"string", "doc": "Software"},
{"name":"software_vers", "type":"string", "doc": "Software version"},
{"name":"license_class", "type":"string", "doc": "License class"},
{"name":"lic_category", "type":"string", "doc": "License calegory"},
{"name":"net_area", "type":"string", "doc": "The NetArea in which this Agent runs"}
{"name":"new_name", "type":"string", "doc": "Additional field added"}
]
}
How data flows through the Streaming Platform
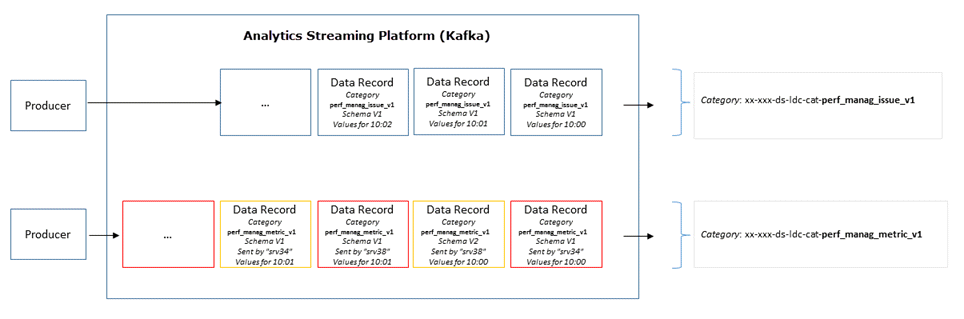
Exporting Data
This feature is only used by DCS.
Data from the Streaming Platform can be exported and there are two types of data export:
- Private for on-premise use
- Sharing with Automic (data that is anonymized)
Automic provides the following API to export data for private on-premise use:
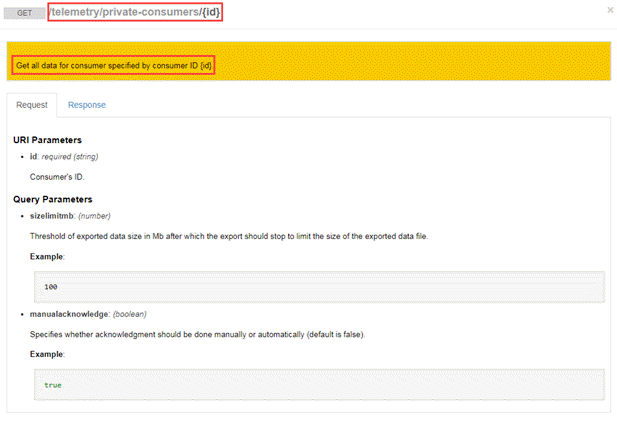
Analytics API exports files in AVRO format. Data record types are described using the AVRO schema for performance and disk space reasons. AVRO is represented in JSON by one of
A JSON string, naming a defined type.
- A JSON object, of the form:
- {"type": "typeName" ...attributes...}
Where typeName is either a primitive or derived type name, as defined below. Attributes not defined in this document are permitted as metadata, but must not affect the format of serialized data.
- A JSON array, representing a union of embedded types.
The AVRO can handle primitive and complex types. See: https://avro.apache.org/docs/1.8.1/spec.html
Currently data injections are done by the Automic product only.
You can use a 3rd-party converter to transform the files in a format that you can easily read, for example in JSON format.
Example Apache "avro-tools": java -jar avro-tools-1.8.x.jar. See: Apache Avro
Data File Structure
This section relates to DCS only.
The AVRO file format:
- The file header is represented by the schema (in JSON text) used to serialize each data record in the file.
- Data records are organized in blocks to optimize later splitting of the file into multiple pieces for parallel processing (with Spark for example) - data blocks can be extracted or skipped without having to de-serialized each block.
See: http://avro.apache.org/docs/1.8.1/spec.html#Data+Serialization
Data records are compact because there is no need to repeat their structure and meta-data for each record, since that's already exposed in the schema in clear JSON text at the beginning of the file.

Consumed Data and Data Retention
Once a consumer has consumed a producer record, the Streaming Platform will offset and only newer records will be consumed by that particular consumer. Any new consumer that subscribes to a producer will consume older records depending on the set retention period.
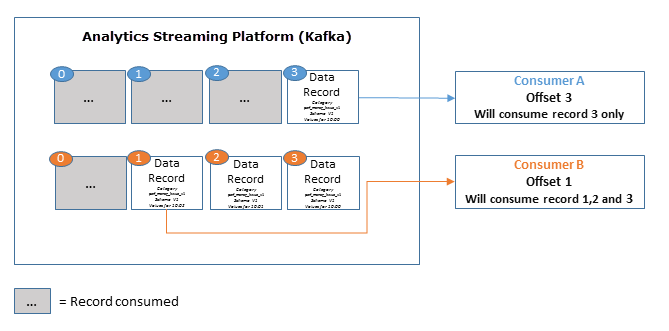
Parallel with the standard implementation of Kafka, the Streaming Platform retains all published records—whether or not they have been consumed. This is carried out using the configurable retention period (default period is 7 days). For example, if the retention policy is set to two days it can be consumed with that time period, thereafter it will be discarded to free up storage space.