Fehlerbehebung in geschlossenen Schleifen
Durch die Integration externer Systeme mit Automic Automation (Automic Automation) können Sie als Systemadministrator oder Workflow-Designer Fehlerbehebungsprozesse automatisieren. Eine automatisierte Problembehebung (oder Problemlösung) ist hilfreich, um routinemäßige Support-Aufgaben und Vorfall-Lösungen zu optimieren. Bei diesen automatisierten Prozessen spielt der Automic Automation-Workflow die zentrale Rolle bei der Durchführung der eigentlichen Fehlerbehebungsaufgaben.
Bei einer Closed-Loop-Fehlerbehebung enthält der Workflow einen zusätzlichen Schritt, um den Endzustand der Fehlerbehebungsaufgabe an das ursprüngliche System zu senden und somit die Fehlerbehebungsschleife zu schließen.
Diese Seite beinhaltet Folgendes:
Vorteile der automatischen Fehlerbehebung
Im Rahmen der täglichen Standard-Betriebsabläufe (SOP) müssen IT-Support- und IT-Administration-Teams ein breites Spektrum kleiner und einfacher routinemäßiger Korrekturaufgaben bewältigen. Diese Aufgaben umfassen ein breites Spektrum an Aktivitäten. Typische Beispiele hierfür sind die Bereinigung des Speicherplatzes, das Zurücksetzen von Passwörtern und Vorgänge für virtuelle Maschinen (VM), z. B. das Neustarten, Zurücksetzen oder Verschieben von VMs.
Für die einzelnen Aufgaben dauert dies jeweils nur ein paar Minuten, aber insgesamt entsteht für die Support-Mitarbeiter ein beträchtlicher Aufwand.
Zu den Vorteilen, die eine automatisierte Fehlerbehebung jeglicher Art für ein Unternehmen bringt, gehören unter anderem:
- Befreiung der Support-Mitarbeiter von Routineaufgaben
- Niedrigere MTTR (Mittlere Reparaturdauer)
- Kontrolliertere, konsistentere und nachhaltige Problemlösung
- Transparenz
- Skalierbarkeit
Übersicht über die automatisierte Fehlerbehebung
Eine automatisierte Fehlerbehebung bei geschlossenen Schleifen mit Automic Automation beinhaltet die Integration eines Automic Automation-Workflows, der die eigentlichen Aufgaben der Fehlerbehebung durchführt, in Ihre Überwachungslösung. Der grundlegende Prozess sieht wie folgt aus:
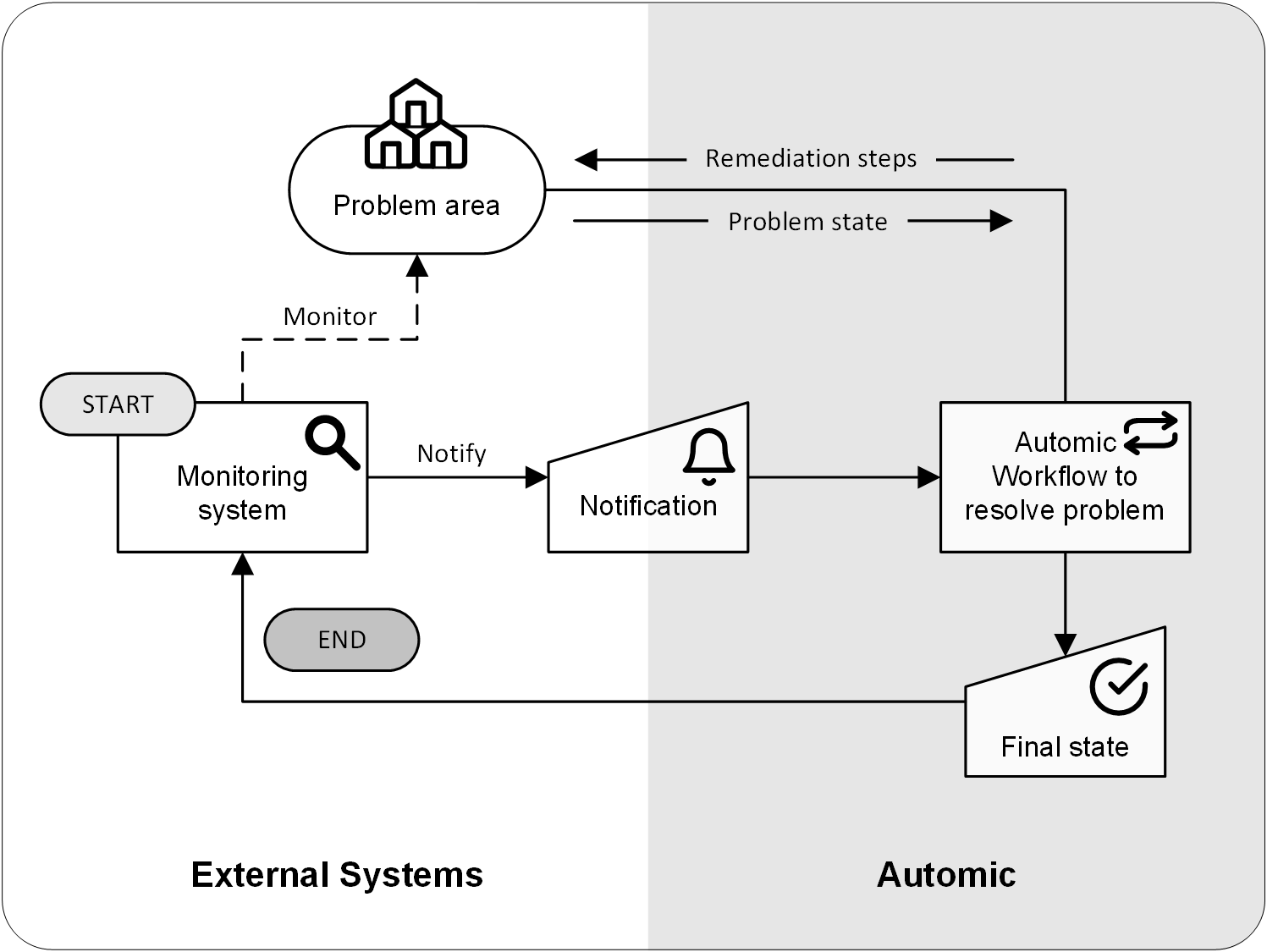
Es gibt immer die fünf Hauptkomponenten:
- Das ursprüngliche System, in dem das Problem oder die Anforderung auftritt
- Ein Überwachungssystem
- Einen Benachrichtigungsmechanismus
- Die Fehlerbehebungsaktionen, die mit einem Automic Automation-Workflow ausgeführt werden
- Einen Mechanismus, der den Endzustand wiedergibt und somit die Schleife der Fehlerbehebung schließt
Wenn die Fehlerbehebung automatisiert ist, wird der Automatisierungsprozess für Ihr Unternehmen dann richtig aussagekräftig, wenn Sie das Feedback zum Endzustand der Fehlerbehebungsmaßnahmen erhalten.
Variation: Hinzufügen eines Vorfall-Managements
Automatisierte Fehlerbehebungen können für eine erfolgreiche ITSM-Strategie (IT-Service-Management) entscheidend sein. Für eine Organisation ergeben sich unter anderem die folgenden Vorteile:
- Befreiung der Support-Mitarbeiter von Routineaufgaben
- Niedrigere MTTR (Mittlere Reparaturdauer)
- Kontrolliertere, konsistentere und nachhaltige Problemlösung
- Skalierbarkeit
- Transparenz des Fortschritts
- Ein Framework für kontinuierliche Verbesserungen Ihrer Vorfall-Auflösung, die besonders dann möglich sind, wenn Daten aus der Fehlerbehebung in geschlossenen Schleifen erfasst und analysiert werden.
Wenn Sie ein Vorfall-Management-Tool integrieren, profitieren Sie am meisten von der automatisierten Fehlerbehebung. Vorfall-Management-Tools sind unter anderem ServiceNow, JIRA oder Request Manager (RM). Da der Workflow den Fehlerbehebungsprozess durchläuft, kann der Workflow die Vorfalldaten mit dem aktuellen Status und den Details der Fehlerbehebung anreichern, bis das Ticket geschlossen wird.
Für die vollständige Automatisierung können Sie den Workflow so auslegen, dass er ein Vorfall-Ticket erstellt, das er sich selbst zuweist. Wenn der Workflow seine Aufgaben durchläuft, wird der Vorfall weiter mit Informationen angereichert. Wenn der Vorfall außerhalb von Automic Automation erstellt wurde, schließt Ihr Prozess Schritte ein, um die Details eines Vorfall-Tickets für die Anreicherung an den Workflow zu übergeben.
Wenn der Workflow das Problem nicht lösen kann, kann der Workflow das Ticket automatisch einer Person oder Gruppe zuweisen, die den Vorfall zur weiteren Analyse und Lösung übernehmen kann.
Durch die Integration des Vorfall-Management-Tools erhalten Sie mehr Transparenz in ihren automatisierten Fehlerbehebungsprozessen.
- Sie können kurzfristig den Verlauf einzelner Tickets verfolgen.
- Langfristig kann die Erfassung vergleichbarer Vorfallsdaten die Analyse von Prozessverbesserungsmöglichkeiten zur Senkung der MTTR für Vorfälle unterstützen.
Andere Variationen
Die Art und Weise, wie Sie die die Fehlerbehebung in geschlossenen Schleifen für Ihre spezifischen Anforderungen implementieren, hängt von den Systemen ab, mit denen Sie arbeiten, und davon, wie ihre Funktionen in Automic Automation integriert werden. Zu den kritischen Schnittpunkten im Prozess gehören unter anderem:
- Benachrichtigung der Automic Automation über den Start des Fehlerbehebungsprozesses
- Wie greift Automic Automation auf das System zu, das die Fehlerbehebung benötigt
- Wie gibt Automic Automation den Endstatus der Fehlerbehebungsaktivitäten an da das ursprüngliche System zurück
Benachrichtigungsoptionen
Eine Benachrichtigung besteht aus zwei Teilen:
- Dem Alarm, der die Benachrichtigung auslöst
Der Alarm, der die Vorfalldetails enthält, kann entweder eine erweiterte Funktion Ihres Überwachungssystems oder eine separate, aber integrierte Anwendung sein.
- Dem Auslöser, der den Workflow zur Fehlerbehebung startet
Sie können diesen zweiten Teil mit einer beliebigen Anzahl von Mechanismen verarbeiten, solange die Vorfalldetails auch an Automic Automation weitergegeben werden. Die gebräuchlichsten Ansätze sind einer oder mehrere der folgenden:
- REST-APIs
Die AE REST-APIs stellen Endpunkte bereit, um Daten zwischen Automic Automation und einer externen Komponente zu veröffentlichen und anzufordern.
- Webhooks, wenn das sendende System für Webhooks eingerichtet ist
Als Webanwendung kann Automic Automation benutzerdefinierte HTTP-Callbacks empfangen, die von Webhooks von externen Quellen gesendet werden.
- Die Event Engine für die Reaktion auf Ereignisse
Die Ereignisverarbeitung mit der Event Engine ermöglicht die Echtzeitfilterung von großen Mengen von Ereignissen aus verschiedenen externen Quellen, um die richtigen Aktionen in Automic Automation auszulösen.
- REST-APIs
Systemautorisierungsoptionen
Um Probleme auf externen Systemen zu lösen, benötigt Automic Automation Zugriff auf die erforderlichen Server, Anwendungen und Dateien. Typische Autorisierungsansätze sind:
- Hinzufügen des Schlüsselzertifikats zum Server des Fehlerbehebungs-Agenten in der Automation Engine
- Übergabe er Authentifizierungsinformationen im REST-Call oder Webhook als Teil der Vorfalldetails
Zurückgeben des letzten Status
In Prozessen zur Fehlerbehebung in geschlossenen Schleifen gibt der Workflow zur Fehlerbehebung den Endzustand der Aufgabe zur Fehlerbehebung zurück. Wie dies geschieht, hängt davon ab, wie der Prozess strukturiert ist.
- Mit einem Vorfall-Management-Tool reichert der Workflow die Vorfalldaten mit den letzten Statusdetails an und schließt das Vorfall-Ticket sogar, wenn die Fehlerbehebung abgeschlossen wurde.
- Anderenfalls kann der Workflow ein REST-Callback an das ursprüngliche System mit dem endgültigen Status und anderen Details senden.
Nachverfolgungsstatistiken für die Analyse
Die Nachverfolgung von Statistiken über die durchgeführten Fehlerbehebungsprozesse ist für eine kontinuierliche Verbesserung des Fehlerbehebungsprozesses unerlässlich. Sie benötigen diese Daten, um festzustellen, wo Sie MTTR für Routineaufgaben senken und Fehler genauer vorhersagen können, um proaktive Wartungsstrategien zu entwickeln.
Sie können diese Statistiken mit einem Vorfall-Management-Tool, CA AutomicAnalytics, einer anderen Analyse-Engine oder einer Kombination von Tools verfolgen. Unabhängig davon, welches Tool Sie verwenden, ist es wichtig, präzise, aussagekräftige und vergleichbare Daten zu sammeln.
Zum Beispiel können Sie Daten erfassen, um die mittlere Reparaturzeit und/oder die mittlere Wiederherstellungszeit zu berechnen. Die Verfolgung der Ausführungslaufzeiten der Workflows für die Fehlerbehebung ist die ideale Grundlage für die Berechnung der "Mean-Time-to-Repair" (der Zeitpunkt vom Start der Reparatur bis zur Wiederherstellung des normalen Betriebs, einschließlich des Tests). Für die mittlere Wiederherstellungszeit, die beim Erkennen des Fehlers beginnt, müssen Sie wissen, wann der Vorfall aufgetreten ist. Wenn die Überwachung außerhalb von Automic Automation ausgeführt wird, muss Ihr Prozess den Zeitpunkt, wann der Vorfall aufgetreten ist, an Automic Automation für Analytics oder an Ihr System für die Statistikerfassung übergeben.
Hinweis: Die Unterscheidung zwischen der Mean-Time-to-Repair und der Wiederherstellung ist wichtig, um vergleichbare Daten für die Analyse sammeln zu können. Für Service Level Agreements (SLAs) und Wartungsverträge kann dies von entscheidender Bedeutung sein.
Siehe auch: